
Noise-Robust Speech Recognition Using Spiking Artificial Neurons
ID# 2013-4113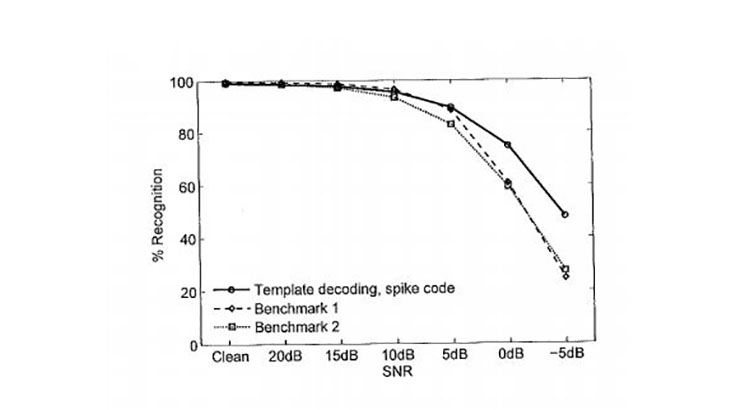
Technology Summary
A novel speech-encoding scheme based on spiking responses of artificial neurons responding to brief acoustic features. The spikes are resistant to corruption by noise. The artificial neurons are trained with clean speech, a mixture of male & female speakers. The inventors devised a template-based method for recognizing the spike sequences, enhancing the ability to deal with temporal variability and noise corruption. System was tested on mixed gender speakers corrupted with babble, car, subway and exhibition hall noise (SNRs 20 dB to -5dB). System was compared to state-of-the-art HMM-based system on an isolated digit recognition task using the AURORA-2 data set. System performs similarly to the benchmark in clean and low-noise conditions, but has significant increase in performance at 0dB and -5dB, with mean recognition rates of 76% (60% benchmark) and 48% (25% benchmark), respectively.
Application & Market Utility
When scaled to large vocabulary speech recognition tasks, the invention’s system can be installed on mobile devices, computers, cars, airplanes and submarines to provide a platform for speech-based interfaces in arbitrary noisy acoustic environments. Potential commercial applications include cell phones, automobiles, military, civilian aviation as well as other communication apparatuses used in loud environments such as first responders.
Next Steps
Future work will evaluate the system’s performance on larger data sets and investigate network implementations of the sequence recognition paradigm. Inventors are seeking licensing partners; Matlab code is available upon request.